Top 50 System Design Interview Questions with Answers (2026): Junior Engineer to Architect
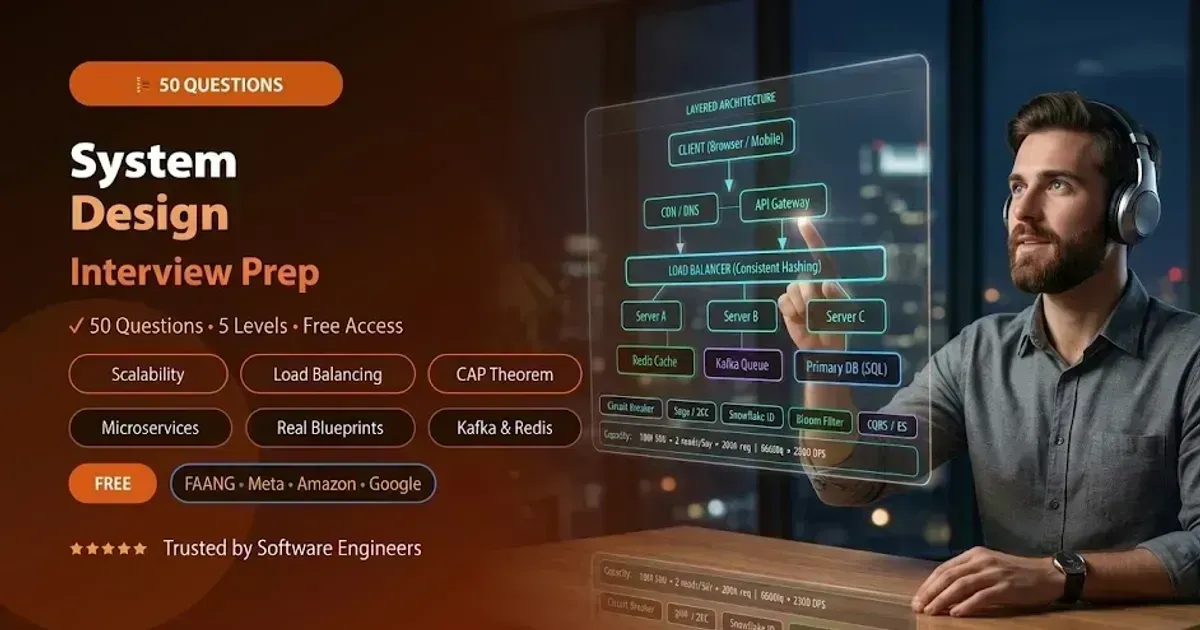
These 50 System Design interview questions cover the complete spectrum of large-scale architecture — from DNS, CDN, load balancing, and caching to advanced topics like consistent hashing, database sharding, the Saga pattern, CQRS, Event Sourcing, and real-world blueprints for designing WhatsApp, Netflix, TinyURL, and Uber — with “Why Interviewers Ask This” insight for every answer.
Contents
- 1.Fundamentals & Networking (Q1–Q10)DNS · TCP/UDP · Reverse Proxy · CDN · REST vs gRPC · API Gateway · Webhooks
- 2.Scalability, Load Balancing & Caching (Q11–Q20)Horizontal Scaling · Consistent Hashing · LRU/LFU · Write-Through · Cache Stampede · Redis
- 3.Databases, Partitioning & Consistency (Q21–Q30)SQL vs NoSQL · ACID · CAP · Sharding · Indexing · Replication · Bloom Filter · LSM Trees
- 4.Microservices, Messaging & Event-Driven (Q31–Q40)Kafka · Circuit Breaker · Saga · DLQ · Rate Limiting · CQRS · Event Sourcing
- 5.Real-World Architecture & High-Level Patterns (Q41–Q50)TinyURL · WhatsApp · Snowflake ID · Netflix · Distributed Locking · Geohash · SPOF · Capacity Estimation
- 6.Common Interview MistakesJumping to solution · Skipping estimation · Over-engineering · Forgetting rate limiting
- 7.Expert Interview StrategyStart with requirements · Capacity estimation · Top-down design · Discuss trade-offs
- 8.Real-World Job ApplicationsBackend / Platform Engineer · Solutions Architect · Engineering Manager
Fundamentals & Networking Interview Questions (Q1–Q10)
What is System Design?
System design is the process of defining the architecture, modules, interfaces, and data for a system to satisfy specified requirements. In software engineering, it refers to architecting large-scale, highly available, and scalable distributed systems that can handle massive user traffic and data volumes.
💡 Why Interviewers Ask This: The baseline definition. It establishes your mindset: you are transitioning from writing single-file algorithms to building global infrastructure.
How does the Domain Name System (DNS) work?
DNS is the "phonebook of the internet." When a user types a URL, the browser queries a DNS resolver, which traverses the Root Nameserver → TLD Nameserver → Authoritative Nameserver to translate the human-readable domain (google.com) into a machine-readable IP address (142.250.190.46).
💡 Why Interviewers Ask This: DNS is the very first step in any web request. Understanding DNS routing and DNS-level load balancing (like AWS Route 53) is mandatory for global architecture.
What is the difference between TCP and UDP?
TCP (Transmission Control Protocol) is connection-oriented, ensuring reliable, ordered, and error-checked delivery of packets — used for HTTPS and file transfers. UDP (User Datagram Protocol) is connectionless, prioritizing high-speed transmission over reliability — used for video streaming, VoIP, and gaming.
💡 Why Interviewers Ask This: Tests foundational networking knowledge to ensure you choose the right transport protocol for different system requirements.
What is a Reverse Proxy?
A Reverse Proxy (like Nginx or HAProxy) sits in front of web servers and intercepts incoming client requests. It provides load balancing, SSL termination, caching, and DDoS protection, hiding the internal server IP addresses from the public internet.
💡 Why Interviewers Ask This: You cannot design a secure, scalable backend without a reverse proxy. It separates the public internet from your internal private network.
What is a Content Delivery Network (CDN)?
A CDN is a geographically distributed network of proxy servers that caches static assets (images, videos, HTML, CSS) at Edge Locations closest to the end user. This drastically reduces network latency, lowers bandwidth costs, and shields the origin server from traffic spikes.
💡 Why Interviewers Ask This: CDN implementation is the standard immediate answer to "How do we reduce latency for global users fetching images?"
Latency vs. Throughput
Latency is the time for a single data packet to travel from source to destination (measured in milliseconds). Throughput is the total volume of data that can be processed within a given timeframe (measured in requests per second or Mbps). You can have high throughput but terrible latency — like shipping a hard drive full of data via FedEx.
💡 Why Interviewers Ask This: A crucial system trade-off — always discuss both dimensions when evaluating architectural choices.
What is the difference between IPv4 and IPv6?
IPv4 uses a 32-bit address space (~4.3 billion addresses) which have been exhausted. IPv6 uses a 128-bit address space, providing a virtually infinite number of addresses along with improved routing efficiency and native IPSec security.
💡 Why Interviewers Ask This: Shows basic network literacy and understanding of internet scaling constraints.
Explain the difference between REST, GraphQL, and gRPC
REST uses standard HTTP methods and URL endpoints — can over-fetch or under-fetch data. GraphQL uses a single endpoint allowing clients to query exactly the data shape they need. gRPC uses HTTP/2 and Protocol Buffers for highly compressed, binary, bi-directional communication — ideal for internal microservices.
💡 Why Interviewers Ask This: Tests API design skills. The choice of communication protocol dictates the efficiency of your system's data transfer.
What is a Webhook?
A Webhook is a user-defined HTTP callback. Instead of a client continuously polling a server, the server proactively pushes real-time data via an HTTP POST request to the client's registered URL the moment an event occurs — e.g., a Stripe payment confirmation.
💡 Why Interviewers Ask This: Tests your knowledge of event-driven architecture and avoiding resource-heavy polling mechanisms.
What is an API Gateway?
An API Gateway acts as the single point of entry into a microservices architecture. It handles cross-cutting concerns like request routing, rate limiting, authentication, payload transformation, and analytics, abstracting the complexity of the backend from the client.
💡 Why Interviewers Ask This: The standard architectural pattern for modern cloud environments like AWS API Gateway.
Scalability, Load Balancing & Caching Interview Questions (Q11–Q20)
Vertical Scaling vs. Horizontal Scaling
Vertical Scaling (Scaling Up): upgrading a single machine with a faster CPU, more RAM, or larger disks — limited by hardware, causes downtime. Horizontal Scaling (Scaling Out): adding more standard machines to a resource pool — theoretically infinite scale, highly fault-tolerant.
💡 Why Interviewers Ask This: The cornerstone of system design. Modern systems default to horizontal scaling to survive massive traffic.
What is a Load Balancer?
A Load Balancer efficiently distributes incoming network traffic across a group of backend servers. It ensures high availability, prevents any single server from becoming a bottleneck, and performs health checks to reroute traffic around failed nodes.
💡 Why Interviewers Ask This: Load balancers are mandatory for horizontal scaling. You cannot build a distributed system without them.
Name common Load Balancing Algorithms
Round Robin: distributes requests sequentially. Least Connections: sends traffic to the server with the fewest active connections. IP Hash: uses the client's IP to consistently route them to the same server — useful for sticky sessions.
💡 Why Interviewers Ask This: Tests your ability to match the routing strategy to the specific workload profile of the application.
What is Consistent Hashing?
Standard hashing (hash(key) % N) breaks catastrophically if the server count changes, requiring massive data reallocation. Consistent Hashing places servers and keys on a conceptual circular hash ring — when a server is added/removed, only k/N keys need to move to the adjacent node.
💡 Why Interviewers Ask This: The most frequently asked algorithm in FAANG system design interviews. It powers DynamoDB, Cassandra, and Redis clusters.
What is Caching?
Caching stores copies of frequently accessed, expensive-to-compute data in a high-speed, temporary storage layer (usually RAM, like Redis or Memcached). Future requests for that data are served significantly faster than querying the primary database.
💡 Why Interviewers Ask This: Caching is the #1 tool for drastically reducing latency and database load.
Compare Cache Eviction Policies: LRU vs. LFU
LRU (Least Recently Used): evicts the item not accessed for the longest time — best for recency-based workloads. LFU (Least Frequently Used): evicts the item accessed the fewest total times — best for overall popularity workloads.
💡 Why Interviewers Ask This: Caches have finite memory. You must know how to intelligently discard old data to make room for new data.
Write-Through vs. Write-Around vs. Write-Back Caching
Write-Through: data is written to cache and database simultaneously — safe, but slower writes. Write-Around: data is written directly to database, bypassing cache — prevents cache flooding. Write-Back: data is written only to cache and acknowledged immediately, asynchronously flushed to DB — blazing fast but risks data loss on cache crash.
💡 Why Interviewers Ask This: Evaluates your ability to balance data consistency against write latency.
What is a Cache Stampede (Thundering Herd)?
When a popular cached item suddenly expires, thousands of concurrent requests all simultaneously experience a cache miss and directly hit the underlying database — potentially crashing it. Solutions: request coalescing (only one request rebuilds the cache) and probabilistic early expiration.
💡 Why Interviewers Ask This: Proves you understand how systems fail at scale. A well-designed caching strategy prevents catastrophic database overload.
Redis vs. Memcached
Both are in-memory key-value stores. Memcached is simple, multi-threaded, and purely for volatile caching. Redis supports advanced data structures (Lists, Sets, Sorted Sets), persistence to disk, pub/sub messaging, and high-availability clustering — making it the industry standard.
💡 Why Interviewers Ask This: Redis usually wins. You must know exactly why it beats Memcached in modern architectures.
What are Sticky Sessions?
A load-balancing technique where a client's requests are continuously routed to the exact same backend server for their session duration. It is generally an anti-pattern in modern design because it hinders auto-scaling and causes uneven load distribution. The correct solution: move session state to an external distributed cache like Redis.
💡 Why Interviewers Ask This: Tests your knowledge of state management. Statelessness is the prerequisite for horizontal scalability.
Databases, Partitioning & Consistency Interview Questions (Q21–Q30)
Relational (SQL) vs. Non-Relational (NoSQL) Databases
SQL databases (PostgreSQL, MySQL) use rigid table schemas, prioritize ACID compliance, and scale vertically. NoSQL databases (MongoDB, Cassandra) use flexible schemas (Documents, Key-Value, Wide-Column), prioritize eventual consistency, and are designed for massive horizontal scaling.
💡 Why Interviewers Ask This: The most important database decision you will make. You must justify your DB choice based on the data structure and scale.
What are the ACID Properties?
ACID guarantees transaction reliability: Atomicity (all operations succeed or all fail), Consistency (data moves between valid states), Isolation (concurrent transactions do not interfere), Durability (committed transactions survive power failures).
💡 Why Interviewers Ask This: The bedrock of financial systems. You cannot design a payment gateway without strict ACID compliance.
What is the BASE Theorem in NoSQL?
BASE is the antithesis of ACID, prioritizing availability: Basically Available (system guarantees a response, even if stale), Soft State (system state may change without input due to eventual consistency), Eventually Consistent (all nodes converge to the same data given time).
💡 Why Interviewers Ask This: Proves you understand the trade-offs made by high-throughput systems like social media feeds.
What is the CAP Theorem?
The CAP Theorem states a distributed data store can only guarantee two of three simultaneously: Consistency (all nodes see the exact same data), Availability (every request gets a response), and Partition Tolerance (system survives network drops). Because partitions are inevitable, designers must choose between CP or AP.
💡 Why Interviewers Ask This: The absolute golden rule of distributed system design.
Database Sharding vs. Partitioning
Partitioning divides a large table into logical pieces within the same database instance. Sharding is a specific type of horizontal partitioning where data is physically distributed across multiple distinct database servers based on a Shard Key (e.g., User ID) — mandatory for systems holding petabytes of data.
💡 Why Interviewers Ask This: Choosing the wrong shard key results in "hot partitions" with uneven load — a critical design mistake.
How does Database Indexing work?
An index is an internal data structure (usually a B-Tree or Hash Table) holding a sorted copy of specific columns with pointers to the actual disk rows. It drastically speeds up SELECT reads at the cost of slowing down INSERT/UPDATE writes and consuming extra disk space.
💡 Why Interviewers Ask This: You must understand database performance tuning. Over-indexing ruins write performance.
Master-Slave vs. Multi-Master Replication
Master-Slave (Leader-Follower): only the Master accepts writes; Slaves serve reads — easy to manage but Master is a write bottleneck. Multi-Master: any node can accept writes and sync with others — scales writes infinitely but introduces complex data conflict resolution issues.
💡 Why Interviewers Ask This: Tests your ability to architect for heavy-read vs. heavy-write workloads.
Strong Consistency vs. Eventual Consistency
Strong Consistency: after a write, any subsequent read from any node instantly returns the updated value — high latency. Eventual Consistency: nodes may be temporarily out-of-sync but will converge to the same value — high availability, low latency.
💡 Why Interviewers Ask This: Focuses heavily on UX. Would you rather a post load instantly (Eventual) or wait 5 seconds for absolute accuracy (Strong)?
What is a Bloom Filter?
A highly space-efficient probabilistic data structure testing set membership. It can definitively tell you if an item is "not in the set" (zero false negatives), but can only say "possibly in the set" (allows false positives). Used by databases to quickly avoid expensive disk lookups for non-existent records.
💡 Why Interviewers Ask This: Advanced memory optimization — a must-know for high-performance database internals.
B-Trees vs. LSM Trees (Storage Engines)
B-Trees (used by PostgreSQL) update data in-place on disk — excellent for heavy-read workloads. LSM Trees (Log-Structured Merge Trees), used by Cassandra, append data sequentially in memory and flush to immutable disk files — exceptionally fast for extremely heavy write workloads.
💡 Why Interviewers Ask This: A senior-level database internals question that separates framework users from true systems architects.
Microservices, Messaging & Event-Driven Interview Questions (Q31–Q40)
Monolith vs. Microservices
A Monolith tightly couples all business domains into one deployable codebase — easy to debug, but hard to scale teams. Microservices decouple domains into independently deployable services communicating over network APIs — scales teams and infrastructure flawlessly, but introduces immense operational and network complexity.
💡 Why Interviewers Ask This: You must articulate that Microservices are an organizational scaling solution, not a silver bullet.
What is Service Discovery?
In a microservices environment, IPs change dynamically as containers scale. Service Discovery (via Consul or ZooKeeper) acts as a dynamic registry — services query it to find the current, active IP address of the service they need to communicate with.
💡 Why Interviewers Ask This: Essential for Kubernetes and containerized cloud environments where server IPs are ephemeral.
Message Queues (RabbitMQ) vs. Event Streaming (Kafka)
RabbitMQ: messages are pushed to queues, consumed by a single worker, then deleted — Point-to-Point. Kafka: messages are appended to an immutable distributed log; multiple consumers can independently read and replay the stream at their own pace — ideal for event sourcing and fan-out.
💡 Why Interviewers Ask This: Tests your ability to architect asynchronous, event-driven systems correctly based on data retention and fan-out requirements.
Explain Exactly-Once Delivery semantics
Message brokers guarantee delivery types: At-Most-Once (might lose data), At-Least-Once (might duplicate data), and Exactly-Once (data arrives exactly one time). Truly guaranteeing exactly-once at the network layer is near-impossible — the correct solution is implementing idempotency at the application layer to safely deduplicate.
💡 Why Interviewers Ask This: A trap question — proves you know the practical solution is consumer-side idempotency.
What is a Dead Letter Queue (DLQ)?
A DLQ is a specialized queue where messages are routed if they cannot be processed successfully after a certain number of retries (due to malformed payloads or persistent downstream failures). It prevents "poison pill" messages from endlessly blocking the main queue.
💡 Why Interviewers Ask This: Proves you know how to build robust, fault-tolerant asynchronous systems that don't crash when faced with bad data.
Rate Limiting: Token Bucket vs. Leaky Bucket
Token Bucket: tokens are added to a bucket at a fixed rate; requests consume tokens — allows sudden short bursts. Leaky Bucket: requests enter a queue and are processed at a strict constant rate — smooths traffic into a steady stream, strictly forbidding bursts.
💡 Why Interviewers Ask This: API defense architecture. You must know how to protect backend services from DDoS or abusive clients.
What is the Circuit Breaker Pattern?
If a downstream microservice repeatedly fails or times out, the circuit "trips" and fails fast, returning a default fallback response without attempting further calls. This prevents cascading system failures and gives the broken service time to recover.
💡 Why Interviewers Ask This: A critical resiliency pattern — shows you understand how to protect a network from being overwhelmed by infinite retries.
What is the Saga Pattern?
Because microservices do not share a database, standard ACID transactions are impossible. A Saga breaks a distributed transaction into a sequence of local transactions. If a step fails, it automatically executes Compensating Transactions to undo preceding steps — e.g., booking Uber: charge card → assign driver; if driver fails → refund card.
💡 Why Interviewers Ask This: The industry standard for handling distributed data integrity across microservice boundaries.
What is Event Sourcing?
Instead of storing just the current state, Event Sourcing stores a sequence of immutable, state-changing events. The current state is derived by replaying the event log from the beginning. It provides a perfect, unalterable audit trail — widely used in financial ledgers and banking applications.
💡 Why Interviewers Ask This: Widely used in fintech and audit-critical systems.
What is CQRS (Command Query Responsibility Segregation)?
CQRS strictly separates the models used to update data (Commands) from the models used to read data (Queries). This allows the read and write databases to be scaled, optimized, and sharded completely independently.
💡 Why Interviewers Ask This: Often paired with Event Sourcing, it is the ultimate architectural pattern for high-performance, read-heavy enterprise systems.
Real-World Architecture & High-Level Patterns Interview Questions (Q41–Q50)
How would you design a URL Shortener (like TinyURL)?
Map long URLs to a 7-character Base62 encoded string. Use a NoSQL Key-Value store (DynamoDB) for O(1) lookups. Generate unique IDs using a Key Generation Service (KGS) or ZooKeeper to prevent collisions. Heavily cache popular links (Redis) and use an API Gateway with rate limiting.
💡 Why Interviewers Ask This: The classic System Design 101 question. Tests encoding logic, hashing, and read-heavy caching architecture.
How would you design a global chat application (WhatsApp)?
Clients maintain persistent WebSocket connections to Chat Servers. A Session Service (Redis) tracks which user is connected to which Chat Server. When User A messages User B, the request hits a message queue, checks the Session Service, and pushes the message to User B's WebSocket. Use Cassandra for high-write message history storage.
💡 Why Interviewers Ask This: Tests real-time communication, connection management, and asynchronous message routing.
How do you generate globally unique IDs at scale (Twitter Snowflake)?
Relying on a single auto-incrementing SQL DB creates a write bottleneck. Snowflake ID generates a 64-bit integer combining a Timestamp + Datacenter/Machine ID + Local Sequence Number — producing sortable, completely unique IDs across all nodes without any central coordination.
💡 Why Interviewers Ask This: Crucial for horizontally sharded databases where multiple nodes must generate primary keys concurrently without collision.
How would you design a Video Streaming Service (Netflix)?
Store original video in Object Storage (S3). Asynchronously trigger a transcoding pipeline to encode video into multiple resolutions (HLS/DASH). Push transcoded chunks to a global CDN. The client player dynamically adjusts requested resolution based on the user's real-time internet bandwidth (Adaptive Bitrate Streaming).
💡 Why Interviewers Ask This: Tests knowledge of heavy asset storage, asynchronous processing queues, and Edge/CDN delivery networks.
What is Distributed Locking and how is it implemented?
In a distributed system, multiple nodes might try to modify a shared resource concurrently. A distributed lock ensures only one node succeeds. Implemented using ZooKeeper, or via Redis using the Redlock algorithm (setting a key with an expiration TTL to automatically release if the holder crashes).
💡 Why Interviewers Ask This: Tests advanced concurrency and preventing race conditions across physical machine boundaries.
How would you design a Proximity / Location-Based Service (Yelp/Uber)?
Standard SQL coordinate queries require full table scans. Use spatial indexing: Geohash (converting 2D coordinates into a 1D alphanumeric string for rapid string prefix matching) or a QuadTree (recursively dividing a map into 4 quadrants for fast nearest-neighbor queries).
💡 Why Interviewers Ask This: Proves you know specialized data structures required for geospatial architecture.
What is a Single Point of Failure (SPOF) and how do you mitigate it?
A SPOF is a system component that, if it fails, stops the entire system from working. Mitigated through Redundancy (deploying multiple instances of databases, load balancers, and network links) and removing all centralized bottlenecks.
💡 Why Interviewers Ask This: High availability (99.999% uptime — "five nines") is impossible if a single server crash takes down the app.
Multi-Region Active-Active vs. Active-Passive Architecture
Active-Passive: one region handles all traffic; if it goes down, DNS routes to a standby region — cheaper, but has downtime during failover. Active-Active: multiple global regions handle traffic simultaneously via Geo-DNS — zero downtime, but requires incredibly complex bidirectional database replication.
💡 Why Interviewers Ask This: Tests your understanding of global disaster recovery and the cost vs. reliability trade-off.
What are Back-of-the-Envelope Capacity Estimations?
Quick math to estimate a system's required storage, bandwidth, and throughput. Example: "100M Daily Active Users × 2 reads/day = 200M requests ÷ 86,400 seconds ≈ 2,300 Requests Per Second (RPS)." System constraints dictate design decisions.
💡 Why Interviewers Ask This: System constraints dictate design. You cannot build a database schema until you mathematically prove how much data it needs to hold.
How would you design a Rate Limiter?
Implement it at the API Gateway level. Use Redis for fast in-memory counter tracking. Apply the Sliding Window Log or Token Bucket algorithm. If a user's IP or API Key exceeds the threshold, return HTTP 429 "Too Many Requests".
💡 Why Interviewers Ask This: A very common, self-contained system design question that perfectly blends algorithms (Token Bucket), infrastructure (Redis), and HTTP protocols (429).
Common Mistakes in System Design Interviews
- Jumping straight to a solution without clarifying requirements: The first 5 minutes should be spent asking about functional/non-functional requirements, expected scale, and read/write ratios. Diving into architecture without knowing if you need 100 RPS or 100K RPS is a red flag (Q49).
- Skipping back-of-the-envelope estimation: Not doing capacity math (Q49) means your design is based on assumptions. Interviewers expect you to calculate storage needs, QPS, and bandwidth before choosing technologies.
- Over-engineering with microservices: Not every system needs 50 microservices (Q31). A well-designed monolith is perfectly valid for many use cases. Jumping to microservices without justifying the operational complexity shows cargo-cult thinking.
- Forgetting about rate limiting and abuse prevention: Most candidates design for the happy path. A real system needs rate limiting (Q36, Q50), DDoS protection (Q4), and dead letter queues for poison messages (Q35).
- Treating the database as infinitely scalable: Saying “we’ll use a database” without discussing indexing (Q26), sharding strategy (Q25), replication topology (Q27), or cache layer (Q15–Q19) shows incomplete thinking.
- Not discussing monitoring and observability: Production systems need health checks, metrics, alerting, and distributed tracing. Interviewers notice when candidates design a system without mentioning how they would monitor it.
Expert Interview Strategy for System Design Roles
- Start with requirements and constraints, every single time. Clarify: Who are the users? What is the expected DAU? Read-heavy or write-heavy? What is the data retention policy? What are the latency requirements (P99)? This shows structured, professional thinking.
- Do capacity estimation early. “100M DAU × 2 requests/day = 200M requests ÷ 86,400s ≈ 2,300 QPS.” Always estimate storage, QPS, and bandwidth (Q49). These numbers drive your architecture — without them, you are guessing.
- Design top-down, then zoom into components. Start with a high-level block diagram (Client → CDN → Load Balancer → App Servers → Cache → Database). Then deep-dive into the most interesting component. Do not get lost in one detail for 30 minutes.
- Discuss trade-offs for every design choice. “I chose Cassandra over PostgreSQL because our workload is write-heavy with eventual consistency requirements (Q21, Q24). If we needed strict ACID, I would choose PostgreSQL with read replicas (Q22, Q27).”
- Always mention failure handling and scalability. For every component, ask yourself: What happens if this fails? How do we scale this? Discuss circuit breakers (Q37), redundancy (Q47), caching strategies (Q15–Q18), and multi-region architecture (Q48).
How These Concepts Apply in Real System Design Jobs
Backend / Platform Engineer
Designs API gateway routing (Q10), configures Redis caching layers (Q15–Q19), implements database sharding with consistent hashing (Q14, Q25), chooses between Kafka and RabbitMQ (Q33), and builds Saga-based distributed workflows (Q38).
Solutions Architect
Makes CAP trade-off decisions (Q24), designs multi-region active-active deployments (Q48), performs capacity estimations (Q49), selects SQL vs NoSQL databases (Q21), and architects CDN strategies for global latency reduction (Q5).
Engineering Manager
Evaluates monolith-to-microservices migration (Q31), reviews circuit breaker and rate limiter configurations (Q37, Q50), makes build-vs-buy decisions for infrastructure components, and ensures observability across the entire system stack.
Conclusion: Master System Design Interviews
These 50 system design questions cover the complete spectrum — from foundational networking concepts like DNS and CDN to advanced architectural patterns like CQRS, Event Sourcing, and the Saga pattern. Understanding both the “what” and the “why” behind each concept prepares you for any FAANG-level system design round.
The best system design answers follow a structured approach: clarify requirements, estimate capacity, design high-level architecture, deep-dive into critical components, and discuss trade-offs. Every architectural choice should be justified with concrete reasoning about scale, latency, and failure handling.
After mastering these questions, practice designing 10 real-world systems: URL shortener, chat application, video streaming, rate limiter, notification system, ride sharing, search engine, social media feed, payment gateway, and file storage. Combine this with Distributed Systems and Coding interview preparation for the strongest possible foundation.
Topics covered in this guide
Topics in this guide: Scalability, load balancers, CDN, database sharding, CAP theorem, consistent hashing, caching strategies, message queues, Saga, CQRS.
For freshers: Client-server model, DNS lookup, basic caching, relational vs NoSQL databases, load balancing algorithms.
For experienced professionals: Microservices architectures, disaster recovery planning, consensus algorithms (Raft, Paxos), partition tolerance mechanisms, global scale database design.
Interview preparation tips: Never jump to a solution; always start with gathering requirements and sizing estimations (QPS, storage bandwidth) to justify your design decisions.
Frequently Asked Questions
Q.What topics are most asked in FAANG system design interviews?
Q.How long should a system design interview answer take?
Q.What is the difference between Kafka and RabbitMQ?
Q.How do you handle database bottlenecks in system design?
Q.What is the best way to prepare for system design interviews?
Found these questions helpful? Share them with your peers.
Common Interview Mistakes
Errors that eliminate candidates
- Giving textbook definitions without showing a concrete this subject use case.
- Skipping trade-offs and answering as if there is only one correct engineering decision.
- Over-answering for 2-3 minutes without structure, metrics, or outcomes.
Expert Interview Strategy
30-second answer rule
- Start with a one-line definition, then explain one real scenario from this subject.
- Use a 3-step structure: concept, practical example, and interviewer intent.
- Close with one trade-off (performance, scale, security, or maintainability).
Real-World Job Applications
These this subject patterns are directly tested for production roles where interviewers expect clear debugging steps, architecture trade-offs, and communication under time pressure.
Conclusion
Mastering these this subject interview questions means explaining concepts quickly, connecting them to real systems, and justifying decisions with practical trade-offs.
Frequently Asked Questions
How should I prepare this topic in 7 days? Focus on high-frequency patterns, rehearse 30-second answers, and revise one practical example per category.
What do interviewers score most? Clarity, structured thinking, and your ability to reason through constraints and trade-offs.